
AI Can’t Reference What It Can’t Resolve
Search used to be a ranking problem. Now it’s a recognition problem.
AI doesn’t link to your site because it found the right keyword—it cites you because it’s confident you exist as a stable, structured entity. If that confidence is low, your brand gets omitted, merged, or paraphrased into someone else’s mention. You disappear—quietly, semantically.
This is how companies with thin content but clean schema end up in Google’s SGE answers, while better sources get ghosted. The machine isn’t judging your expertise—it’s resolving your identity.
If your brand isn’t an entity, your content is just noise.
LLMs, SGE, and generative interfaces aren’t looking for top results—they’re looking for answerable nodes. They rely on structured sources, co-citation patterns, and entity graphs to determine which names to surface, reference, or summarize.
So if your brand:
- Uses multiple names across channels
- Lacks schema for Organization or Brand
- Has no presence in canonical data sources (Wikidata, Crunchbase, etc.)
- Appears in content but not in structured markup
…then you’re functionally invisible to AI. It can’t reference what it can’t resolve.
What breaks when resolution fails?
- Your content gets cited… but your brand doesn’t
- Competitors with less authority get surfaced because they’re better structured
- You get skipped in carousels, answer boxes, and summaries
- LLMs hallucinate your name or conflate you with a lookalike
- You lose ownership of your own narrative in AI outputs
Resolution isn’t just recognition, it’s attribution. And in an ecosystem where generative tools are the new front page, attribution is everything.
Start with entity integrity. And this checklist.
Before you chase rankings or refine content, fix how machines see you:
- Use schema.org/Organization with sameAs and consistent brand naming
- Canonicalize your brand presence across all owned and syndicated surfaces
- Submit structured profiles to Wikidata, Crunchbase, and any vertical-specific sources
- Audit internal mentions and metadata for naming consistency
- Check how AI tools summarize you today—and where you’re absent
We’re no longer chasing Google’s latest algorithm update. Now we’re out to build brands that are referenceable.
Structured Signals Are the New Brand Guidelines
Your brand style guide tells designers how to size your logo. Your structured data tells AI how to recognize you.
And only one of those governs whether you’ll appear in an SGE answer or a ChatGPT response.
Traditional brand systems focus on human readability—fonts, tone, visuals, messaging. But for AI, the asset that matters most is structured data: the schema markup, entity relationships, and consistent metadata that make your brand machine-legible.
If your structured signals are missing or inconsistent, AI can’t differentiate you from a product, a blog post, or a completely unrelated brand.
Schema isn’t decoration—it’s identity architecture.
AI doesn’t scan your homepage and understand context like a person. It interprets metadata, structured markup, and known reference nodes. That means every schema field you skip is another clue you’ve failed to send.
At minimum:
- Your Organization schema needs a name, url, and sameAs links to official profiles
- Each author should have a Person schema with a consistent identifier across platforms
- Your logo should match across your Brand schema, favicon, and public listings
- Use mainEntity and about fields to define topical authority clearly
- Apply isPartOf and publisher to connect your brand to your content with intent
This is what lets machines anchor you—not just crawl you.
Where most SEO teams miss:
- They use schema reactively—just to pass error checks
- They leave sameAs fields empty or outdated
- They don’t map product and content entities back to a parent brand
- Their schema is technically valid, but semantically useless
Structured data is now the language of inclusion.
If you don’t tell AI who you are, it will guess—or ignore you entirely.
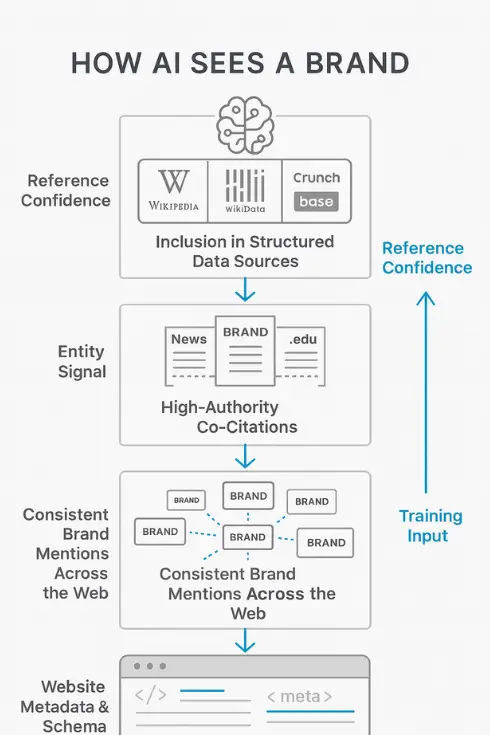
The Role of High-Authority Co-Occurrence
The fastest way to earn trust in an AI-driven ecosystem isn’t links—it’s adjacency.
When your brand shows up next to trusted entities in structured, crawlable content, it doesn’t just gain exposure. It gains credibility in the machine’s mental model. AI systems—SGE, ChatGPT, Perplexity—evaluate how often and where your brand co-occurs with known, stable identities. This is how they determine whether to cite you, summarize you, or ignore you.
It’s not about who links to you. It’s about who you’re seen with—and whether that context is machine-readable.
AI doesn’t evaluate content the way traditional SEO systems do. It doesn’t care if a domain has a million backlinks if those backlinks don’t teach the model anything.
Instead, LLMs learn by pattern recognition:
- Is your brand mentioned near known category leaders?
- Do those mentions show up in crawlable formats like structured blog content, contributor bios, speaker lists, or media features?
- Are the co-mentions consistent across multiple trusted domains?
The model doesn’t just ingest data—it builds a trust graph. If you’re never mentioned in proximity to reliable entities, you’re never placed in the network that matters.
What breaks if this isn’t done:
- You invest in link-building, but your citations never train the model
- You’re quoted in media pieces that never get structured or crawled
- Your competitors show up in SGE answer boxes—not because they’re better, but because they’re consistently referenced with trusted names
- Your domain authority rises, but your brand authority stays invisible to AI
In other words: You’re getting “seen” but not learned.
It’s time to start looking at co-occurrence as more than just a PR tactic. It’s a machine learning signal.
To become referenceable:
- Place your brand next to known entities in schema-rich environments
- Prioritize contributor bylines, podcast guest spots, expert roundups, and speaker lists that use structured markup
- Avoid thin or unstructured mentions that don’t reinforce context
- Treat every brand-adjacent sentence like a semantic anchor
Because in a world where LLMs stitch together context from patterns, adjacency is attribution.
Canonicalization Isn’t Just for URLs Anymore
You already know how URL canonicals work—one master version, everything else pointing to it.
Now apply that same logic to your brand.
AI systems need a single, consistent representation of your company across every structured surface they crawl. But most brands still fragment their identity across “Inc.” vs “LLC,” www vs non-www, different social handles, and even inconsistent product naming. Humans may know it’s the same business. AI doesn’t.
And when it can’t resolve your identity cleanly, it either skips you—or makes you someone else.
In generative search and LLM training, ambiguity = exclusion.
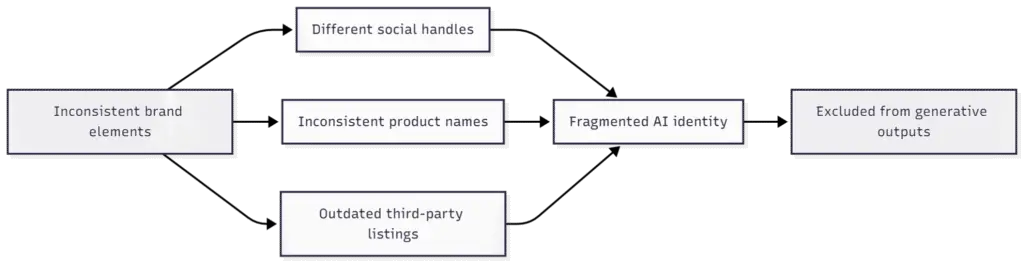
Your brand is one node in a sprawling web of entities. If it appears under five slightly different names, at three slightly different URLs, or with inconsistent schema across content types, the model won’t consolidate those into a single concept. It will assume they are separate, unstable, or unreliable.
And unstable entities don’t get surfaced.
- Your homepage doesn’t match the brand listed in your schema
- Third-party listings reference you with outdated names or wrong domains
- Product reviews, PDPs, and UGC pull in different brand variations
- Your company gets cited but doesn’t resolve to your domain—so AI doesn’t associate the mention with your brand at all
- Competitors with cleaner entity footprints get included in carousels, overviews, and generative answers while you get dropped
In other words, your built visibility—but the model didn’t connect the dots.
Think of your brand as a canonical entity, not a label.
To make that entity resolvable across systems:
- Use the same name format across schema, social profiles, listings, and structured bios
- Ensure sameAs properties in Organization schema point to live, verified profiles
- Align product naming in PDPs, knowledge bases, and support content
- Standardize meta titles, social handles, and author attributions
- Submit corrections to third-party data sources where inconsistencies live (e.g., Crunchbase, Data Axle, ZoomInfo)
Because AI doesn’t assume sameness—it only trusts structured confirmation–your goal should be to eliminate ambiguity at the crawl layer.
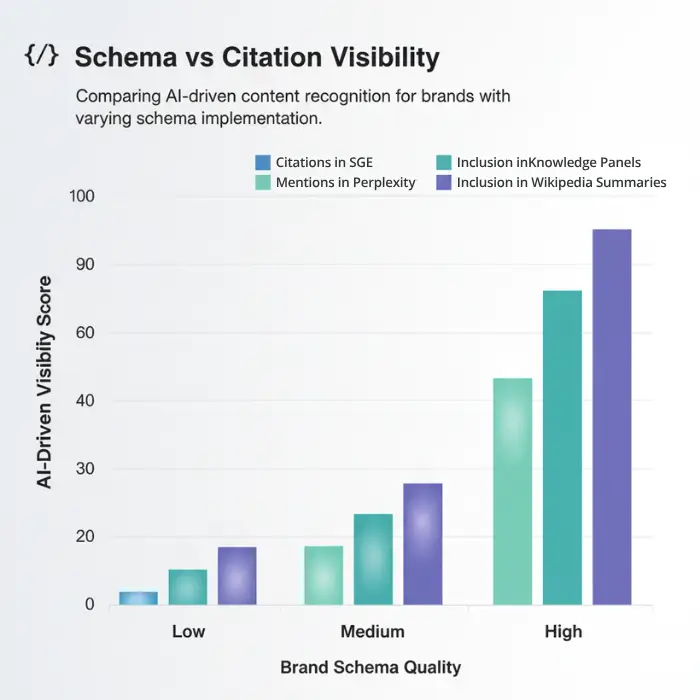
Where LLMs Learn: Crawl Maps and Source Bias
Your content doesn’t train AI just because it exists.
LLMs like GPT-4, Claude, Gemini, and Meta’s LLaMA are trained on curated subsets of the web—not the open internet. And the sites they prioritize aren’t necessarily the biggest. They’re the most trusted, crawlable, and semantically rich.
If your brand isn’t present in those high-trust, high-crawl environments, it doesn’t get included in the training corpus. Which means you’re not part of the model—and not part of the market.
This is why some competitors get cited in ChatGPT or Perplexity, and you don’t—even if they have weaker content. It’s not about the writing. It’s about the source layer.
We’re entering an era of closed-corpus visibility. The era of the Black Box.
- Google’s SGE is pulling from a reduced set of sites with high-quality structured data
- OpenAI has prioritized Wikipedia, Common Crawl, and manually curated datasets
- Perplexity favors sources with schema markup and high clickstream engagement
- Meta LLaMA models ignore many niche domains entirely unless explicitly referenced elsewhere
This isn’t about writing better content—it’s about being in the crawl path. If…
- You can’t rank in generative results because your content isn’t in the model
- Your brand doesn’t show up in zero-click answers, even when your site holds the most accurate info
- Your competitors gain category authority by simply existing in crawl-priority zones
- You push out schema and blog content, but none of it gets indexed in the LLM layer
Then you might be publishing the best content in the world, but the models either can’t see it or are choosing to ignore it.
If you want AI systems to cite you, they need to learn from you. To do that, you have to show up where the training data lives:
- Submit structured brand and product data to Wikidata, DBpedia, and OpenCorporates
- Get referenced (with schema) on high-trust sites that appear in Common Crawl and SGE datasets: Wikipedia, Crunchbase, TechCrunch, Product Hunt, Stack Overflow, GitHub, LinkedIn
- Push for content placement in structured ecosystems—not just publications
- Use Schema.org types that align with the way LLMs interpret web knowledge (e.g. FAQPage, HowTo, Product, Organization, Person)
AI isn’t trained on content quality. It’s trained on content location.
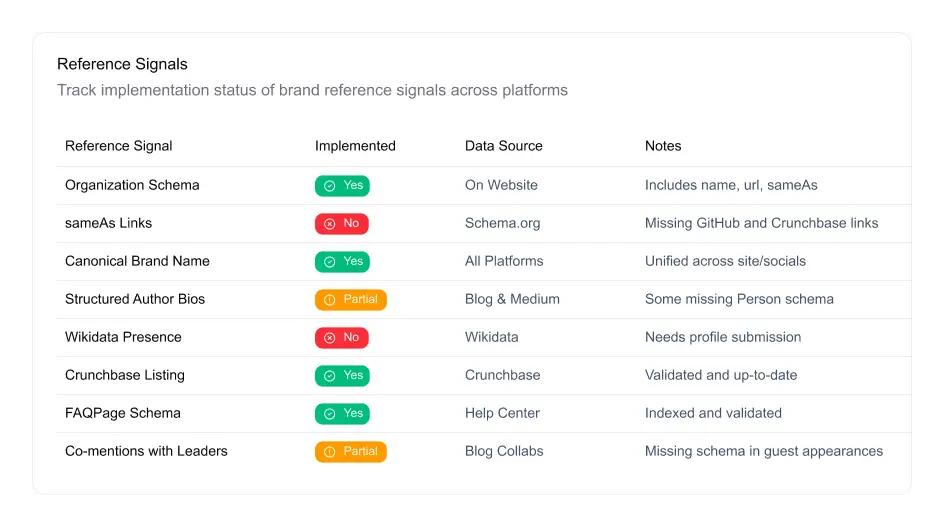
Reference Engineering as a Visibility Strategy
You can’t optimize for a SERP that doesn’t exist. But you can engineer your brand to be referenced—consistently, structurally, and at scale.
Visibility no longer comes from rankings. It comes from inclusion in the mental models machines use to generate, summarize, and suggest. And the only way to earn that inclusion is to architect your brand as a trusted, repeatable node in the AI content ecosystem.
It’s not a campaign. It’s not a technical patch. It’s reference engineering—and it’s now a core function of modern SEO, content ops, and comms.
The old playbook—keywords, backlinks, page speed—isn’t really obsolete. It’s just incomplete.
AI-driven surfaces like Google’s SGE, ChatGPT, and Perplexity no longer depend on traditional search signals alone. They rely on:
- Entity consistency
- Structured brand representations
- Cross-surface co-occurrence
- Presence in trusted, crawlable knowledge graphs
If you’re not intentionally building reference layers into your content, schema, and PR strategy, you’re forfeiting long-term visibility in the systems that are replacing search.
- Your domain ranks, but your brand doesn’t get cited
- You show up in traditional results but get excluded from AI answers
- Product pages perform in ads but fail to appear in carousels, assistants, or summaries
- LLMs continue hallucinating, skipping, or misattributing your identity
- You fall behind competitors who structure their references and train the model before you do
Search is evolving—and passive visibility doesn’t cut it anymore.
You don’t need to chase attention—you need to train attribution.
That means:
- Structuring every mention of your brand across all surfaces
- Reinforcing your identity through high-authority co-occurrence
- Aligning schema, naming, profiles, and knowledge base entries
- Designing content not just for people, but for inclusion in machine-generated narratives
Reference engineering isn’t a feature, it’s the base you build your brand on.
Brand visibility lives in systems that predict what to say before users even ask—and if you’re not part of that memory, you’re not part of the market.

