
It’s Already Happening; Don’t Wait for AI to Make Shit Up About You
Your brand is already in the model. The only question is: what does the model think it knows about you?
Large language models don’t wait for your permission to summarize your business. They’ve already crawled your site, scanned your press hits, interpreted your about page, and connected the dots between your name, your product, and whatever nearby entities they trust more.
This is the first shock for most brand teams: LLM visibility isn’t opt-in. Whether it’s ChatGPT offering recommendations, SGE summarizing company overviews, or Perplexity surfacing “alternatives,” your presence—or absence—has already been resolved by systems you didn’t configure.
And if you’re not shaping that resolution, you’re at the mercy of it.
Impressions used to come from headlines, search rankings, and mentions. Now they’re increasingly mediated by LLMs.
- Chatbots summarize your brand in user prompts
- Auto-generated shopping guides pull product info from trained models
- SGE results reduce entire websites into two-sentence overviews
- Voice assistants give recommendations based on model memory
- Research agents rewrite your position using partial data
If you’re not in the model—or worse, you’re misrepresented—your visibility flatlines, and your brand equity decays in silence.
What breaks when you’re not actively shaping your LLM presence?
- Outdated messaging becomes the model’s “truth”
- Competitors get cited in your category while you’re omitted
- Brand name gets conflated with unrelated entities (esp. with shared acronyms or similar names)
- Press wins get ignored because they weren’t structured or reinforced
- Users get AI-generated summaries that don’t match your positioning, value props, or even facts
You didn’t get excluded because of bad PR. You got excluded because you weren’t resolved confidently enough to include.
You can’t fix what’s already been trained—but you can shape what comes next.
Here’s the play:
- Start with audit: Search your brand across ChatGPT, Perplexity, Gemini, Claude, SGE
- Map the discrepancies between your official narrative and the machine-generated one
- Identify where your brand is referenced without reinforcement (single-source mentions, no schema, no co-occurrence)
- From here, you’ll build your reference architecture—not to rank, but to train
This is no longer PR for readers; it’s PR for models. So if you’re not shaping how LLMs explain your business and your products, someone else already has.

LLMs Cite Patterns, Not Press Hits
The era of “one big win” is over.
Getting quoted in TechCrunch doesn’t guarantee inclusion in ChatGPT. A Forbes feature won’t get you mentioned in Perplexity if it’s buried behind a paywall. Your brand’s credibility no longer comes from splashy hits. It comes from semantic density across citable, crawlable, structured sources.
Large language models don’t think in articles. They think in patterns. They don’t cite because you’re notable. They cite because you’re resolvable, repeated, and contextually reinforced in the places they trust.
So if your PR strategy is still focused on headline volume instead of model inclusion—you’re broadcasting into silence.
LLMs don’t index like Google. They compress the web into weighted networks of relationships.
- A mention without schema may as well not exist
- A press hit without entity linking is a dead-end
- A quote that doesn’t appear elsewhere doesn’t move the needle
- A one-off podcast interview won’t beat consistent co-occurrence with known entities
This is what AI is really looking for: consensus, not novelty.
When your PR stays stuck in those old metrics…
- Your biggest press wins are invisible to language models
- You get citations in trade outlets, but competitors dominate AI recommendations
- Your name shows up inconsistently across sources—so the model never resolves you confidently
- You overinvest in placements that don’t train the right systems
- Your thought leadership circulates—but doesn’t accumulate
It’s not that you’re missing coverage. You’re missing reinforcement.
PR today isn’t about being seen, it’s about being cited by machines.
This means:
- Shift from vanity placements to patterned co-citation
- Choose outlets that are schema-rich, crawlable, and indexed by Common Crawl
- Use consistent language, structured bios, and entity-linked metadata across every piece
- Repurpose thought leadership to appear in multiple trust-weighted domains
Your goal isn’t just to get quoted anymore. Now, it’s to become undeniably referenceable—so that models cite you not because they discovered you, but because they can’t not.
Building an LLM-Ready Authority Graph
LLMs don’t index in isolation. They map relationships. If your brand doesn’t appear near other high-authority entities, it doesn’t just get missed, it gets misunderstood.
This is where traditional PR breaks down. Coverage without structure. Mentions without proximity. Interviews that live in silos. LLMs treat these like fragments, not signals.
To be truly referenceable, you need more than backlinks. You need an authority graph: a network of high-quality citations, co-mentions, and structured associations that reinforce what your brand is, does, and belongs next to.
This isn’t link-building. It’s trust architecture. It’s data merchandising. LLMs build internal models of trust based on:
- Co-occurrence (your brand + known entities in same paragraph or page)
- Entity reinforcement (repeated structured mentions across sources)
- Contextual similarity (appearing near other brands in your category or market)
- Schema support (structured data that validates relationships)
The more consistently you show up near known entities—media outlets, partners, topics, competitors—the more confidently the model can cite you.
This is how models “decide” that your brand belongs in the answer set.
Without an authority graph:
- Your best content fails to influence models because it’s isolated
- You get mentioned in niche blogs, but not in proximity to recognized entities
- LLMs associate your brand with unrelated topics due to weak surrounding context
- You rely on backlinks when models are reading for relational density, not PageRank
- You wait for coverage to accumulate, but never structure it to signal trust
Authority without adjacency gets lost in compression.
Want to show up in SGE, ChatGPT, or Gemini? Start thinking like the model.
Build your authority graph deliberately:
- Publish guest content on entity-rich, structured domains
- Ensure every contributor bio is schema-marked and sameAs linked
- Target interviews and bylines where your brand appears next to trusted brands
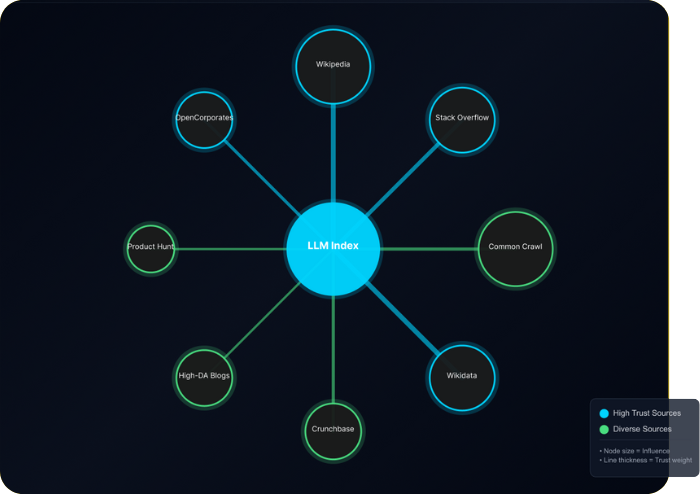
- Submit brand profiles to Wikidata, Crunchbase, OpenCorporates, Product Hunt
- Use internal linking to reinforce entity proximity across your own content hub
Build your graph right and you’ll be building more than just credibility. You’ll be training the model to see you as credible—because of who surrounds you, and how often.

Not All Links Matter—Some Train Models
You don’t need more coverage. You need the right kind of coverage—the kind that actually makes it into the model.
Most PR teams assume all links are equal. But LLMs don’t crawl the open web indiscriminately. They pull from selective, high-authority corpus—often referred to as “gold sets.” These include sites with editorial oversight, structured data, and wide linkage to other trusted entities.
If your press hits live outside those gold sets—paywalled, unstructured, or on low-trust domains—they may be great for social proof, but they won’t help you train the model.
And that’s the delta: exposure without inclusion.
LLMs are trained using filtered versions of the internet—Common Crawl snapshots, curated datasets, proprietary indexes (like Google’s or OpenAI’s). Just because your article is published doesn’t mean it’s seen. And even if it’s seen, it may not be used.
What these systems prioritize:
- Crawlability (robots.txt open, no paywalls)
- Schema clarity (structured entities, relationships)
- High-trust domains (Wikipedia, .gov, .edu, top-tier publishers)
- Contextual linkage (your brand appearing near known, resolved entities)
- Multi-source consensus (your brand saying the same thing in multiple places)
A backlink from a blog post with no structure is a whisper. A schema-backed co-mention on a gold set domain? That’s signal. So if you’re optimizing for visibility but not trainability, this is what you can expect:
- You invest in PR that earns links—but none make it into training data
- Your most important interviews live behind paywalls
- Thought leadership lands in silos instead of networks
- You don’t get cited—even when your perspective is better
- AI-generated outputs ignore you because the model never saw you
You didn’t get skipped because you lacked authority. You got skipped because your content wasn’t in the model’s memory.
In the LLM era, your link strategy isn’t about traffic—it’s about training.
Here’s the rundown:
- Prioritize crawlable, schema-rich placements
- Partner with publishers that already show up in Perplexity, SGE, or ChatGPT citations
- Publish to high-trust, structured platforms (Wikidata, Crunchbase, Product Hunt, structured blogs)
- Replicate messaging across multiple indexed sources to create consensus signals
- Check your coverage: Is it in the Common Crawl? Is it cited in Wikipedia? Does it show up in AI answers?
Because if a link doesn’t train the model, it doesn’t scale your visibility. It’s time to stop counting PR wins and start counting citations that stick.
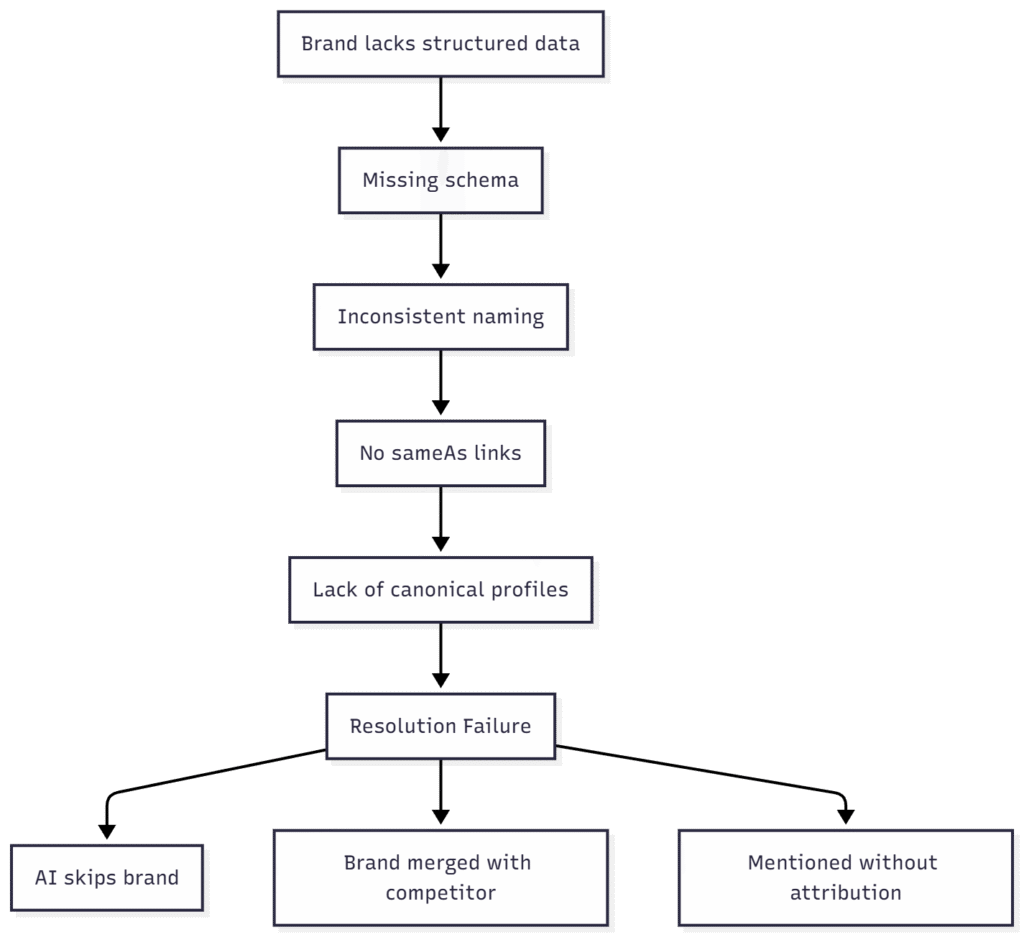
Reputational Risk in Generative Outputs
If AI can cite you, it can misquote you. And if your brand presence isn’t structured, reinforced, and current, it will.
Most teams focus on what AI leaves out. But what it includes incorrectly can be just as dangerous—especially when that content scales across search, assistants, content tools, and conversational interfaces.
LLMs aren’t malicious. They just fill gaps with guesses. And if your brand isn’t well-defined across trusted sources, you’re giving the model permission to hallucinate.
This isn’t theoretical. It’s already happening.
The same systems that recommend your brand also summarize it. But LLMs aren’t citing your website—they’re pulling from compressed webs of partial information.
What if…
- You changed your positioning. But the model didn’t.
- You rebranded. But the model still shows your old name.
- You clarified a product category. But the model confuses it with competitors.
- You gave interviews. But so did someone with a similar brand acronym.
And now? You show up in AI search as something you’re not.
When hallucinations happen, it’s rarely because the model is broken. It’s because your brand wasn’t resolved with enough clarity to override confusion.
Without LLM reputation management:
- Generative answers present inaccurate or outdated messaging
- Your brand gets conflated with unrelated entities or competitors
- Misinformation from user forums or third-party content gets amplified
- AI-generated content tools produce false descriptions of your business
- Voice assistants serve recommendations that don’t include you—or worse, include someone else in your place
And unlike traditional PR crises, these don’t flare up visibly. They degrade brand equity silently, one invisible output at a time.
So yeah, LLM hygiene is now part of brand hygiene. Here’s how to do it:
- Regularly audit AI summaries across ChatGPT, Perplexity, Claude, Gemini, SGE
- Use schema and structured data to declare canonical brand elements (name, description, category, relationships)
- Submit changes to Wikidata, Crunchbase, and other high-authority profiles
- Reinforce your brand story through multiple trust-weighted sources
- Track discrepancies—then trace them back to where the model may have learned the error
Perfection is not the goal. Instead, aim to remove ambiguity before the model fills it for you. Hallucination prevention should now be part of your brand strategy.
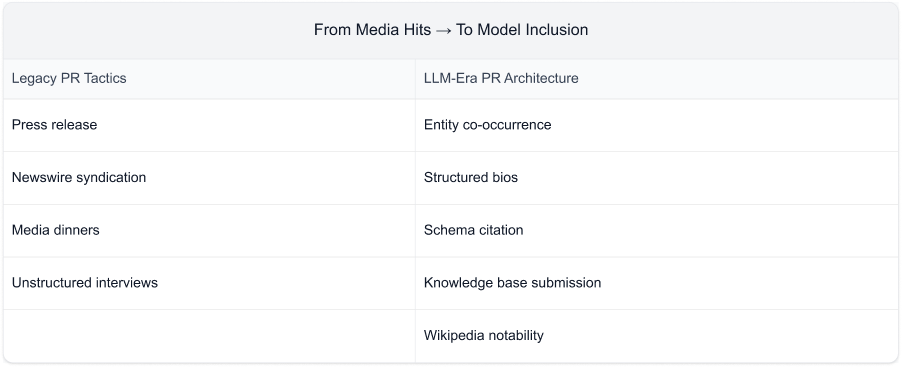
Your New PR Stack: Structured, Trusted, Distributed
The old PR stack was media lists, press releases, and placement spreadsheets.
The new one?
Schema markup. Entity validation. Crawl path engineering. Citation mapping. Authority graphs.
Because in the age of LLMs, your brand doesn’t just need exposure—it needs machine legibility.
It’s no longer enough to tell a good story. You need to embed that story in the structures AI systems use to decide what’s true, relevant, and worth repeating.
LLMs don’t care what you say about yourself. They care what others say about you—and whether that data is clear, consistent, and crawlable.
If your brand isn’t structured, it won’t be referenced. If it’s not cited in trust-weighted places, it won’t be surfaced. If it’s not reinforced across canonical profiles, it will be ignored or misrepresented.
AI isn’t just a channel. It’s the new infrastructure for brand perception.
When your PR isn’t built for AI…
- Your visibility doesn’t scale—because your citations don’t reinforce
- Your best messaging gets buried in unstructured formats
- You overinvest in “coverage” that models don’t even ingest
- You rely on anecdotal success (“we were featured here”) instead of reference momentum
- You lose narrative control to the machine layer
Put simply: you show up everywhere except where it matters most.
The new PR stack looks like this:
- Structured metadata on every owned and earned page
- Schema.org markup across content, bios, product pages, and org profiles
- Entity reinforcement across Wikidata, Crunchbase, LinkedIn, and Google KB
- Citation density in high-authority, crawlable sources
- Co-occurrence strategy to appear near known, trusted entities
- Crawl visibility audits to ensure your content is actually seen by training sets
Don’t think of it as a pivot. Think of it as an upgrade in which brands no longer win by being the loudest.

